我发现,很多人对大模型有一种根深蒂固的误解——他们觉得 ChatGPT、Claude 这些东西,是真的在”思考”,真的在”理解”,甚至真的在”推理”。
我最开始也是这么认为的
大模型表现得太像了。
但如果你真的想用好它,甚至想在它身上构建应用,你就得先搞清楚一件事:
它的本质,是在猜。
不是贬义的那种猜。是一种极其精密、经过海量训练校准过的猜测。
下面部分内容参考来源于:
https://github.com/datawhalechina/hello-agents
一切的起点:人类想造一个会思考的机器
1956 年,达特茅斯会议。几个学者聚在一起,正式提出了”人工智能”这个词。
他们的出发点很朴素:人类靠符号和逻辑思考,那机器只要能操作符号、执行逻辑,不就能思考了?
这就是符号主义(Symbolism)。
核心假设来自 Newell 和 Simon 在 1976 年提出的物理符号系统假说:智能的本质就是符号的计算与处理。只要系统能操作符号,理论上就能产生通用智能。
顺着这个思路,人们造出了专家系统。
原理很简单:把领域专家的知识编成规则,IF 患者发烧 AND 喉咙红肿 THEN 可能是扁桃体炎,然后让机器顺着规则推理。代表作是医疗诊断系统 MYCIN,在某些领域,它的诊断准确率甚至超过了普通医生。
听上去很厉害。
但它有个致命问题:知识是人工编的。
现实世界的知识是无穷的,常识是隐性的。你能告诉机器”火是热的”,但你没法告诉它”把手放进火里会疼,而且疼了以后你应该把手抽回来,而不是继续放着思考疼痛的哲学意义”。
更要命的是,规则外的情况一来,系统直接崩溃。脆,很脆。
1980 年代中期,专家系统的热潮退去,AI 迎来了第二次寒冬。
另一条路:别编规则,让机器自己学
与此同时,另一批人走了完全不同的方向。
他们说:人脑不是靠规则运转的,人脑靠的是神经元之间的连接权重。那我们造一个模拟神经元网络的系统,让它从数据里自己学规律,不就行了?
这就是联结主义(Connectionism)。
1986 年,Hinton 等人重新推广了反向传播算法,神经网络终于有了训练的方法。机器第一次可以从原始数据里自动调整参数、学习模式——不需要人手动编知识。
但当时算力不行,数据也不够,联结主义雷声大雨点小。
又沉寂了将近二十年。
直到 2012 年,Hinton 的学生用一个深度卷积神经网络 AlexNet,在图像识别竞赛上碾压了所有传统方法。
这一下,炸了。
深度学习时代正式开始。
语言的问题:序列,是个难题
图像还好处理。一张图,像素矩阵,输进去,分类出来。
但语言不一样。语言是序列——词和词之间有顺序,有依赖,有上下文。
“我没说他偷了钱”这一句话,加上不同的重音,能有七种意思。
为了处理序列,人们造出了 RNN(循环神经网络),后来又有了 LSTM(长短期记忆网络)。
思路是:每处理一个词,把前面的信息压缩成一个”隐藏状态”,带着它处理下一个词。有点像人在读书,一边读一边在脑子里更新理解。
LSTM 加入了门控机制,能更好地记住重要信息、遗忘无关内容,一度是 NLP 领域的标配。
但它有个根本缺陷:必须串行处理。
你必须先处理第一个词,才能处理第二个词,才能处理第三个词……序列越长,越难训练,越容易遗忘早期的信息。并行?做不到。
这就是 2017 年之前 NLP 领域最大的天花板。
Transformer:把”注意力”这件事做成了架构
2017 年,Google 发了一篇论文,题目叫《Attention Is All You Need》。
论文提出了 Transformer 架构,完全抛弃了循环结构,只用注意力机制(Attention Mechanism)。
核心思想很直觉:人在理解一句话的时候,不是线性扫描每个字,而是会把注意力放在最相关的部分。
比如”银行倒闭了,我的钱没了”——理解”钱”的时候,你的注意力会自然聚焦到”银行”和”没了”上,而不是”了”这个语气词。
Transformer 把这个”注意力”数学化了:
Attention(Q, K, V) = softmax(QK^T / √d_k) × V每个词生成三个向量:Query(我想找什么)、Key(我能提供什么)、Value(我的实际内容)。Query 去和所有词的 Key 做内积,算出相关度,再用这个相关度加权求和所有词的 Value。
结果:每个词都能直接”看到”序列里的所有其他词,一步到位。
不需要串行,可以并行计算。序列长?没关系,注意力全局覆盖。
这一下,训练效率直接起飞。
当时的两条路,以及后来的选择
Transformer 出来的时候,NLP 领域其实有两条路在竞争:
一条是 LSTM 路线:继续优化循环网络,加更多门控,做更复杂的记忆机制,处理更长的序列依赖。这条路走了很多年,大家都以为它是终点。
另一条是 Attention 路线:干脆抛弃序列假设,用注意力机制建模任意位置之间的关系。
Transformer 选了后者,而且走得很彻底。
两年后,OpenAI 拿 Transformer 的解码器部分做了 GPT-1,Google 拿编码器部分做了 BERT。
GPT 只保留解码器,目标极其简单:预测下一个词。
不断地、反复地、在海量文本上预测下一个词。就这一件事。
BERT 选了编码器,做双向理解,适合分类、问答这类任务。
最后,时间证明了 GPT 路线赢了。不是因为 BERT 不好,而是”预测下一个词”这个目标,足够简单,足够通用,又足够强大。
大模型的本质:猜,一直猜,猜得越来越准
现在可以说那个核心问题了。
大模型在做什么?
它在做的事情,从始至终只有一件:给定前面的文字,预测下一个最可能出现的词(或 token)。
你问它”法国的首都是什么”,它不是查了数据库,不是推理出来,而是:这串文字后面,最可能跟着的是”巴黎”。
你让它写代码,它不是理解了需求再设计,而是:这段描述后面,最可能出现的是这样的代码结构。
你让它解数学题,它不是真的在演算,而是:这道题的下一步,在训练数据的分布里,最可能是这个写法。
这就是为什么大模型会”幻觉”——它不是撒谎,它只是在概率分布里取了一个不正确但看起来合理的样本。
这就是为什么温度(Temperature)参数能控制它的”创意”——温度高,概率分布更平,选到低概率词的机会更大,输出更”发散”;温度低,直接选最高概率,输出更”稳定”。
这就是为什么 CoT(思维链)有效——让模型一步步写出中间过程,等于给”下一个词预测”提供了更好的上文,每一步的预测都更准确。
它不是在思考,它是在猜,只不过猜得太准了。
这里举一个简单的例子:我有一根长 5.5m 的竹竿,要通过一个高 4m、宽 3m 的门,能不能通过,直接给出回答即可。
国内不少模型,包括我测试过的 DeepSeek、豆包、Qwen、Kimi,给出的答案都是”不能”。
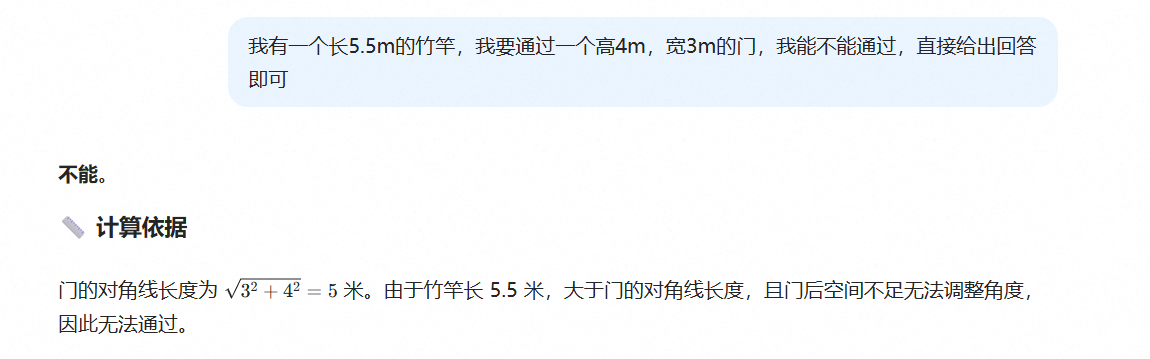
它们的”推理”是这样的:门的对角线是 √(3² + 4²) = 5m,而竹竿有 5.5m,5.5 > 5,所以过不去。
但实际上,只要把竹竿直着拿(即垂直于门所在的平面),径直穿过去,就能顺利通过。门的高和宽根本限制不了一根直着穿门的竹竿,真正能挡住它的是墙的厚度——而题目压根没给墙的厚度。
为什么模型会齐刷刷地答错?
因为这道题”长得太像”另一道经典题了——“搬着长杆绕过墙角 / 把杆斜放进门框”。那类题的标准解法就是算对角线。模型一看到”竹竿 + 门 + 能不能通过”,下一个最可能出现的词,就是对角线公式那一套。它没有在脑子里把竹竿真的穿过门,它只是匹配到了训练数据里最像的那个模板,然后顺着往下猜。
这就是”猜”的典型翻车现场——不是不会算,而是压根没在思考这道题本身。
那为什么最新的模型又能答对了?
有意思的是,我发现现在最新的 Gemini 和 Claude 已经能答对这道题了。
这是不是说明它们”真的理解空间了”?
恐怖的是,并没有。原因其实更朴素,而且恰好印证了这篇文章的主题:
第一,这道题火了,正确答案进了训练数据。
这道”竹竿过门”的陷阱题在网上传开之后,连带着它的正确解法(“直着穿过去”)一起,被新一轮训练数据吸收了进去。于是对最新的模型来说,这串文字后面最可能跟着的,不再是对角线公式,而是”直着拿就能过”。
它依然是在猜,只是这次猜的方向被训练数据掰正了。答案从分布里的低概率区,挪到了高概率区。
第二,推理模型不那么容易”抄近路”了。
最新的模型大多经过了强化学习的推理训练(你能看到它先输出一长串思考过程)。这种训练让模型不再一上来就抓最表面、最相似的那个模板,而是被鼓励一步步把情境拆开、自己检查一遍”对角线这个约束在这里到底成不成立”。
多写出来的这些中间步骤,等于给”下一个词预测”垫了更扎实的上文,每一步都猜得更稳,于是更容易绕开那个陷阱。
但请注意——这两条原因,没有一条是”模型真的在脑子里转动了那根竹竿”。
一条是答案进了分布,一条是它愿意多猜几步。本质还是猜,只是猜得更准、更不容易被表面相似性带偏了。
这也是为什么我说,看透它比用好它更重要:今天它答对了竹竿,明天换一道还没进训练数据的新陷阱题,它照样会自信地翻车。
但猜得准,本身已经是奇迹
这里要说清楚一件事:说大模型是在”猜”,不是在贬低它。
能猜到这个程度,已经是人类历史上从未有过的东西。
GPT-4 的参数量在数千亿量级,训练数据是互联网上几乎所有的公开文字,训练计算量要用几万张 GPU 跑几个月。这些参数里,压缩了人类文明几百年积累的文字和知识。
当模型足够大、数据足够多,会发生一件神奇的事:涌现(Emergence)。
某个参数规模之后,模型突然就会做它从来没被显式训练过的事情:数学推理、逻辑类比、多语言翻译、写诗、编程……
这不是设计出来的,是在”猜下一个词”这个极简目标下,自发涌现出来的能力。
所以大模型才让人迷惑——它看起来太像在思考了。它能解释因果,能理解情绪,能做多步推理。
但这背后,是概率分布,不是意识。
从大模型到智能体:给猜测装上手和脚
大模型猜得再准,它也只能输出文字。
而现实世界需要行动:搜索、调用 API、操作文件、执行代码、和其他系统交互。
于是出现了智能体(Agent)。
智能体的本质是:给大模型配上工具,让它不只是说”我帮你查一下”,而是真的去查,拿回结果,再继续推理,直到任务完成。
目前最主流的范式是 ReAct:Reasoning + Acting。模型先思考(Reasoning),决定要做什么动作(Acting),执行完看结果,再思考,再行动,循环下去。
2025 年被称为”Agent 元年”——大家发现,与其把精力放在训练更大的模型,不如专注于怎么让现有模型更好地使用工具、规划任务、协作执行。
技术的重心,从”怎么猜得更准”,转向了”怎么用好这个会猜的家伙”。
智能体的两条出路
到了 2026 年,智能体领域开始出现分歧,两种思路在竞争。
第一条路:把模型做得更强。
这条路的逻辑很直接:既然 Agent 频繁出错,那就让它更聪明。用更多数据、更大参数、更好的强化学习,让模型本身具备更强的规划能力、更准确的工具调用判断、更少的幻觉。
这条路没错。模型能力确实在进步,o3、DeepSeek R1 这类推理模型的出现,让 Agent 在复杂任务上的成功率有了明显提升。
但问题是:模型永远会犯错,而且在你意想不到的地方犯错。
你不可能等到模型完美了再部署 Agent。
第二条路:把环境做得更好。
2026 年 2 月,HashiCorp 联合创始人 Mitchell Hashimoto 提出了一个新概念:Harness Engineering(驾驭工程)。
核心思想只有一句话:
“每次 Agent 犯错,你应该花时间重新设计它运行的环境,让它将来不再犯同样的错。”
它的逻辑是:Agent 出问题,往往不是模型不够聪明,而是运行环境没设计好。
一个有意思的数据佐证了这个观点:LangChain 团队在没有换模型的情况下,仅仅优化了 Agent 的运行框架和约束机制,Terminal Bench 评分就从 52.8% 提升到了 66.5%,全球排名从第 30 跳到第 5。
模型一点没变。变的是环境。
Harness Engineering 主要做四件事:
- 上下文工程:给 Agent 提供高质量的活文档(AGENTS.md),而不是让它在黑暗里猜测该做什么
- 架构约束:用自动化的 Linter、CI 检查,把 Agent 不该做的事在流程上拦住
- 反馈循环:让 Agent 审查 Agent,自动测试覆盖失败路径,让错误信号能及时反馈
- 熵管理:用专门的 Agent 持续清理技术债、修正过时文档,防止环境腐烂
Harness一词来自马具——缰绳、马鞍、嚼子——这是一套引导强大但不可预测的动物的完整装备。驾驭工程不是去削弱 AI 的能力,而是为它打造一套黄金缰绳,让它跑得又快又稳。
它改变的不只是技术,还有工程师的角色——从写代码的人,变成设计 Agent 运行环境的人。
两条路并不对立
这两条路没有谁对谁错,它们解决的是不同层面的问题。
“模型更强”是在提升猜测的准确率。
“Harness Engineering”是在减少猜错之后的损害,并且让错误变成可以修复的系统缺陷而不是玄学事故。
真正可靠的 Agent 系统,两者都需要。
但如果你现在就要落地一个 Agent,我的判断是:与其等更强的模型,不如先把环境设计好。
因为一个设计良好的约束环境,能让普通的模型表现得像高级模型。
而一个糟糕的环境,再强的模型也会在里面翻车。
最后
AI 走了七十年,从符号主义到专家系统,从联结主义到深度学习,从 Transformer 到大模型,从大模型到智能体。
每一次转折背后,都是对”机器怎么才算智能”这个问题的重新理解。
符号主义说:逻辑推理就是智能。
联结主义说:从数据里学规律就是智能。
大模型说:把人类所有文字里的规律都压缩进来,猜得足够准,就是智能。
我不知道哪个答案是对的。
但我知道,当大模型猜错的时候,你得能认出来。
不然你以为它在思考,其实它只是在猜一个听起来合理但完全不准确的答案。
会用的前提,是先看透它。